
失效和維修費用占任何資產密集型系統壽命周期成本的很大一部分。例如印度航空公司將收入的
13%
~
15%
用于維護,這是僅次于燃料成本的第二高成本
。同樣地,
2002
年美國國防總預算的約
1/3
用于維護和維修活動。因此,工業需要一種具有成本效益的維護策略。在所有的維護策略中,基于狀態的維護
(Condition Based Maintenance,CBM)
最具成本效益。采用有效的
CBM
方法可避免不必要的停機,還可降低維護成本。然而,
CBM
的成功實施需準確預測部件或系統的
剩余使用壽命
( Remaining Useful Life,RUL)
。診斷是一種基于監測參數來預測
RUL
的技術,方法可大致分為基于物理的診斷方法和數據驅動的診斷方法。基于物理的診斷方法是特定于缺陷的,需對系統有全面的理解。然而,數據驅動的診斷方法采用以往觀察到的狀態監測數據
(
這些數據來自一組在類似條件下從事相同工作的相同機器
)
,然后概率性地得出系統的
RUL
預測。這樣的一組機器通常被稱為機群。
從機群獲得的數據可能包含具有多重失效模式(如疲勞、磨損、腐蝕、塑性變形和失穩)的部件的失效信息。球軸承可能由于內圈、外圈、球或保持架的失效而失效。狀態監測數據(如振動)通常用于診斷過程中失效的預測。這些失效模式通常非獨立,之間可能存在一些復雜甚至未知的關系。一種失效模式的存在可能導致或引發另一種失效模式,因此被稱為非獨立失效模式。根據失效模式的不同,這些數據可能在診斷方法中顯示出不同的行為或模式。如果這些失效行為或模式沒有得到恰當的識別和處理,那么可能會作為數據集的噪聲源,導致對失效概率的低估或高估。因此,在構建診斷模型前需識別失效數據中可能存在的失效行為,并對其進行相應的處理。
近幾十年來,多重失效模式的診斷模型已引起廣泛研究。Wang開發了具有非獨立失效模式的機械部件的可靠性模型,推導出聯合概率密度函數,將各失效模式相關聯。該模型的缺點是在不同的失效模式之間假定了線性相互關系,這可能不適用于大多數情況。Huang和Askin介紹了具有多重競爭失效模式的電子設備的可靠性模型。該研究同時考慮了退化和災難性失效,并推導出概率密度函數來預測設備的失效。由Zhang等人提出的混合Weibull比例風險模型可結合整個系統的多重失效模式。結合各失效模式的歷史壽命和狀態監測數據對模型參數進行評估。將多重失效模式的失效概率密度函數按比例混合來估計系統的可靠性和失效時間。Son介紹了用于估計機電伺服系統可靠性的數學模型。這些研究工作主要集中在具有多重失效模式的系統或部件的可靠性估計。具有多重失效模式的系統的診斷模型在文獻中很少見。
多重失效模式的有效模型診斷一般基于獨立失效模式或獨立狀態監測信息等假設而開發,例如Moghaddass和Zuo開發了一種具有多狀態退化和2種獨立失效模式的廣義系統診斷模型。只要各失效模式的狀態監測指標相互獨立,該方法有效。然而,在許多實際情況下,狀態監測指標極易受部件中出現的全部或多重失效模式的影響。因此,根據不同的指標區分失效模式可能比較困難。
Pradeep Kundu等開發了一種考慮多維狀態監測特征的具有多重非獨立或獨立失效行為的球軸承的通用診斷方法。由于缺乏關于失效模式的準確信息,因此采用聚類方法和變點檢測算法 ( CPDA) 對具有不同失效行為的軸承進行分離。 這種分離有助于分析每套軸承的失效模式,進而有助于降低與不同失效相關的噪聲,同時開發診斷模型。分離后,采用基于GLL- Weibull的非線性參數化建模方法開發了RUL預測模型。針對單一失效行為,為不同類型的失效行為開發了不同模型。對于具有多重失效行為的軸承,通過綜合單一失效行為模型的失效密度來估計模型參數和 RUL 。 將這一獨特的程序應用于目前的工作有助于非常準確地預測RUL。此外,該模型同時對模型參數進行了估計,并選擇了與軸承退化直接相關的最佳特征或狀態監測指標。最終,有助于減少RUL預測所需的時間和步驟。與其他基于統計或人工智能( AI)的RUL預測方法相比,單獨使用諸如基于遺傳算法(GA)、基于相關性或基于馬氏距離(MD)的特征選擇方法是RUL預測模型的前身。
數
據采集
研究所用的軸承退化數據取自PRONOSTIA平臺(圖1),該試驗平臺用于測試和驗證滾動軸承診斷和預測方法。使用該數據集的權限取自IEEE PHM 2012委員會。由圖1可知,試驗平臺上安裝了2個加速度計,分別測量水平和垂直方向的振動信號。加速度計以10 s為間隔測量原始振動信號,采樣頻率為25.6 kHz,這意味著在10 s的間隔內有2 560個數據點可用。當振動信號幅值超過20 g 時,試驗軸承視為失效。

圖 1 PRONOSTIA 平臺
研究所用數據對應于7套軸承在1 800 r/min和4000 N的運行條件下的失效數據。每套軸承的失效時間見表1。所有這些軸承運行至失效,也就是缺陷并非預置到軸承中。因此,軸承可能由于任何一種可能的失效模式(如球、套圈、保持架或其組合) 而失效,因此,需識別數據中是否存在多種信息。
表 1 7 套軸承的失效時間
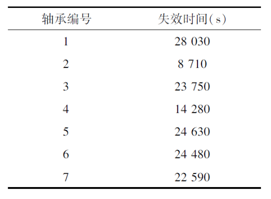
此外,少量的訓練數據和試驗期間的高變異性(8 710 ~28 030 s)對失效預測提出了額外的挑戰。因此,研究處理的問題是降低由于數據中存在多重失效行為而產生的噪聲,并對 RUL 進行準確的預測 。
RUL計算流程
所提出方法的流程圖如如2所示。
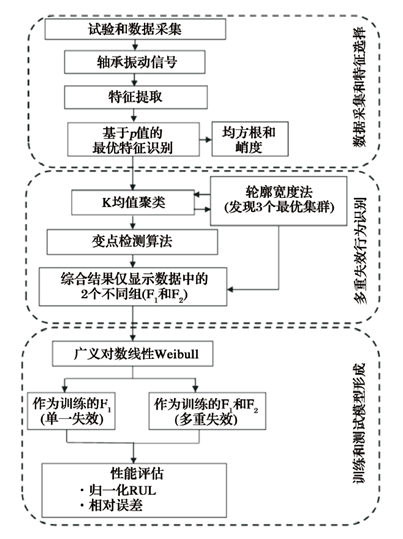
圖2 提出的RUL預測方法
結論及后續工作
研究聚焦點是 識別數據中的多重失效行為,并將這些信息與球軸承的 RUL 預測方法相結合 。目前大多數診斷模型的工作都考慮了單一失效模式存在的假設,而Pradeep Kundu等研究提出了一種對具有多重失效模式的部件進行擴展式診斷分析的方法,而這一部件會導致數據中的多重失效行為。結果表明,K均值聚類算法和CPDA能很好地理解數據中可能出現的失效模式。這一理解對于準確預測軸承的RUL非常有用。目前工作獲得的結果有望為多重失效模式的診斷建模提供突破。
這項工作還可推廣到許多其他領域,例如狀態推斷領域。這類通用問題的目的是通過一組信號或癥狀來推斷系統的狀態。采用CPDA識別出的變點也可看作是軸承退化狀態,因此,提出的CPDA可用于狀態推斷問題。同時可使用馬爾科夫、半馬爾科夫或隱馬爾科夫分析等方法,通過計算從一種狀態轉移到另一種狀態的概率來預測各部件的RUL。
(來源:軸承雜志社)


軸研所公眾號 軸承雜志社公眾號
Copyright © 2019 洛陽軸承研究所有限公司, All Rights Reserved 備案號:豫ICP备18028303号-3

營銷熱線
0379-64367521
0379-64880626
13693806700
0379-64880057
0379-64881181
 返回
返回